一. 索引的定义
索引:在计算机科学领域,索引指的是辅助存储引擎高效获取数据的一种数据结构。索引在MySQL的整体架构中的存储位置如下图所示:
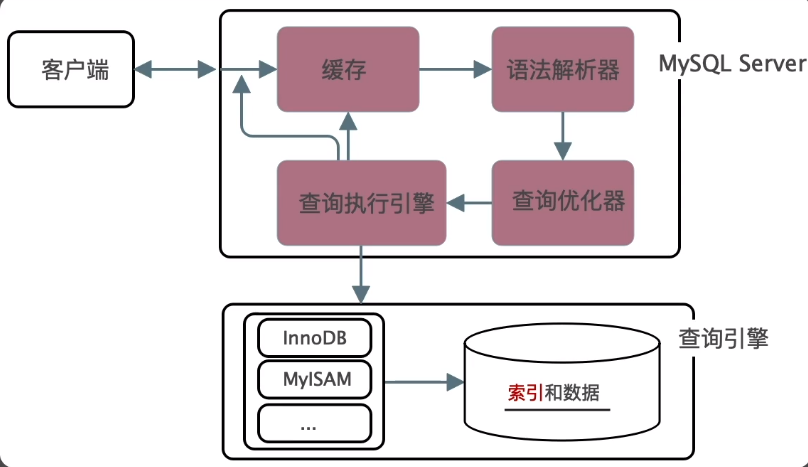
从图中也可以看出来,索引是存储在引擎层的而不是服务层,因此不同的存储引擎所能支持的索引类型也不尽相同。
二. 索引的分类
2.1 数据结构角度
从数据结构的角度划分,MySQL支持的索引类型主要有以下几大类:
- Hash 索引
- B+ Tree 索引
- Full-Text 全文索引
以下表格描述了各个主要存储引擎所支持的索引类型:
| InnoDB | MyISAM | Memory | |
|---|---|---|---|
| B+Tree 索引 | Yes | Yes | Yes |
| Hash 索引 | No | No | Yes |
| Full-Text 索引 | Yes | Yes | No |
从MySQL5.5.5 开始, InnoDB已经成为了MySQL默认首选的存储引擎,而其支持的索引类型中,我们用的最多的非B+ Tree 索引莫属。
B+ Tree 的数据结构大致如下图所示:

从图中可以看出,B+ Tree 索引的数据全部存储在叶子节点上,而且叶子节点相邻的数据记录之间通过单链表的方式链接,正是因为这一点,B+ Tree 索引具备支持范围查询的能力,而这是 Hash 索引所不具备的。B+ Tree 索引的搜索时间复杂度为 O(logd N) . d 即为树的度,即B+ Tree 所允许的子节点的个数最大为d个。相比较红黑树(一种平衡二叉树的变种)而言,红黑树同等结构下搜索复杂度为 O(log N). 此处可以看出,红黑树 结构在搜索数据时,比采用B+ Tree 结构要经历更多次搜索次数,也就意味着需要更多次的磁盘I/O. 因此同样是树形结构,采用B+ Tree 还是略胜一筹。综合上边叙述来看,B+ Tree 索引在数据搜寻方面显然拥有更多的适应场景,因此它才被广泛采用。
2.2 B+ Tree 索引
由于B+ Tree 索引几乎是用的最多的一种索引类型,因此有必要这里着重说明一下。
B+Tree 索引适用的查询场景主要有以下几类:
- 全值匹配。指的是和索引中所有用到的列进行匹配,比如有一个employee表,其中有复合索引
idx_name_age使用到了 (name, age)这两列。当进行类似查询select <field1> [field2]... from employee where name='xxx' and age = 'xx'时,就会使用索引 idx_name_age 进行全值匹配。 - 最左前缀匹配,在employee 表中,还是情形1中提到的
idx_name_age索引,查找所有name 中以 “chen” 开头的雇员时,根据最左前缀匹配可以使用上idx_name_age索引。 - 匹配范围值。比如employee表中有 idx_age 索引,进行
select select <field1> [field2]... from employee where age between 16 and 55这样的查询时,会用到 idx_age 索引来进行数据搜寻。 - 精确匹配某一列并范围匹配另外一列。假如现在employee 表中有个 idx_age_name 索引,用到的列是(age, name)。 要查询所有22岁姓陈的雇员,如
select * from employee where age = 22 and name like 'chen%'时,就会用上idx_age_name索引。 - 只访问索引的查询。这种情况就好比情形1中在employee表中只查询name和age,这种查询只需访问索引,而无须回表访问数据行,通常称之为
索引覆盖。
2.3 Hash 索引
Hash 索引基于哈希表实现,只能用于精确匹配索引所有列的查询。对每一行数据,存储引擎都会计算一个hash code, 而且不同行计算出来的hash code 也不一样。Hash 索引将所有的hash code存储在索引中,同时在哈希表中保存指向数据行的指针。 在MySQL 中,只有Memory 引擎才显式的支持 Hash 索引。
2.4 Full Text 索引
全文索引是一种特殊的索引方式。它查找匹配的是文本中的关键词,而不是直接比较索引中的值。一般而言,不在数据库层面直接使用Full Text 索引,而是把全文索引的工作交给类似 Elastic Search 这样的搜索引擎去完成。
(To be continue…)

